Language AI in 2026: A Snapshot
Multimodality, efficiency, evaluation, and the forces shaping what language technology becomes.
NLPLLMMultimodalAI GovernancePython
NLPLLMMultimodalAI GovernancePython
The Natural Language Processing series traced the field from hand-crafted rules through transformers, pre-training, scaling, retrieval, alignment, and compound AI systems. Each generation resolved the previous generation's bottleneck and introduced new constraints. The current moment is different. There is no single architectural bottleneck to clear. Instead, the field's trajectory is shaped by a set of intersecting forces: models expanding beyond text, efficiency gains compressing capabilities into smaller footprints, evaluation frameworks struggling to keep pace, and regulatory structures taking shape around deployed systems.
These forces interact. Efficiency improvements accelerate open-model proliferation, which increases deployment surface area, which amplifies the urgency of both evaluation and regulation. This article is a snapshot: where language technology stands in early 2026, and which open questions will determine where it goes next.
The transformer was designed for sequences of text tokens, but attention is modality-agnostic. Vision transformers (ViT) demonstrated that images, split into patches and embedded as token sequences, could be processed by the same architecture. Multimodal models (GPT-4o, Gemini, Claude) now process images, audio, code, and text within a unified architecture, producing shared representations across modalities.
This convergence is consequential. Document understanding, chart interpretation, visual reasoning, and video analysis were previously separate engineering disciplines, each with its own model family and data pipeline. A compliance workflow that once required OCR, layout analysis, text extraction, and classification can now be handled by one model call that reads the document image directly. Audio-native models combine speech recognition, understanding, and generation without intermediate text transcription.
The trajectory points toward universal context windows that accept any input modality and produce any output modality. The practical ceiling is context length and computation, not architecture.
The first wave of capable language models required hundreds of billions of parameters. GPT-3 (175B parameters, 2020) was followed by PaLM (540B, 2022). The second wave inverted this trajectory. Llama 2 70B (2023) matched or exceeded GPT-3.5 on many benchmarks. Phi-2 (2.7B, 2023) and Gemma 2 (9B, 2024) achieved results that would have required models 10–50x larger two years earlier.
Several techniques drive this compression. Knowledge distillation transfers capabilities from large teacher models to smaller student models. Quantization (reducing weight precision from 32-bit to 8-bit or 4-bit) cuts memory and compute requirements with minimal accuracy loss. Improved training data curation, longer training runs on higher-quality tokens, and architecture refinements (grouped-query attention, mixture-of-experts routing) each contribute independently.
The following chart illustrates how each generation of models achieves higher benchmark performance at the same parameter count, or equivalent performance at a fraction of the parameters.
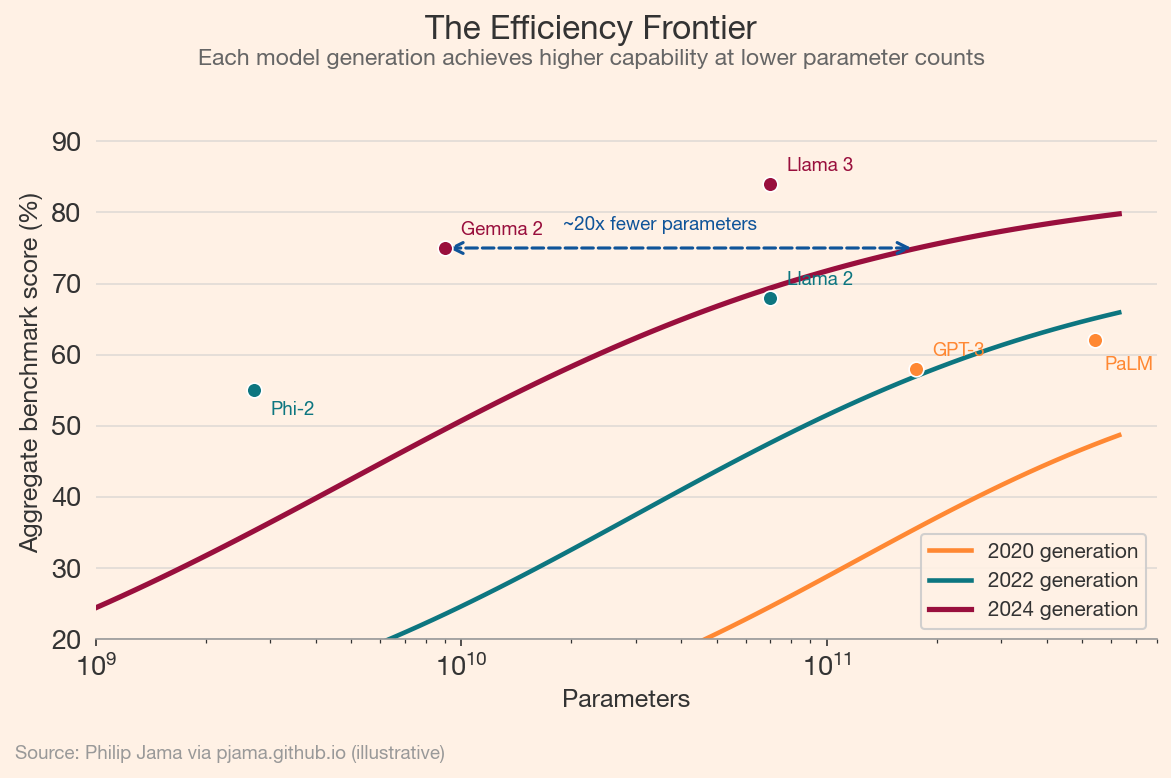
When a 9B parameter model running on a single GPU matches the performance of a 175B model from two years prior, the cost and latency barriers to deployment drop by orders of magnitude. On-device inference, offline operation, and privacy-preserving local processing become practical for the first time.
Benchmarks are saturating faster than new ones can be designed. MMLU, built to test broad knowledge, saw scores climb from 43% (GPT-3, 2020) to above 90% within three years. HumanEval for code generation followed a similar trajectory. GSM8K for math reasoning went from a meaningful discriminator to a near-solved problem within a single model generation.
The problem is not just saturation but relevance. High benchmark scores and real-world utility are increasingly decoupled. A model that scores 95% on MMLU may still fail at tasks enterprises care about: following complex multi-step instructions, maintaining consistency across long documents, or correctly handling edge cases in domain-specific workflows. Informal qualitative testing by practitioners has become a common complement to automated metrics, a signal that the field's measurement tools have not kept pace with its capabilities.
This chart shows how top-model scores on several major benchmarks have converged toward ceiling performance, compressing the useful discriminative range.
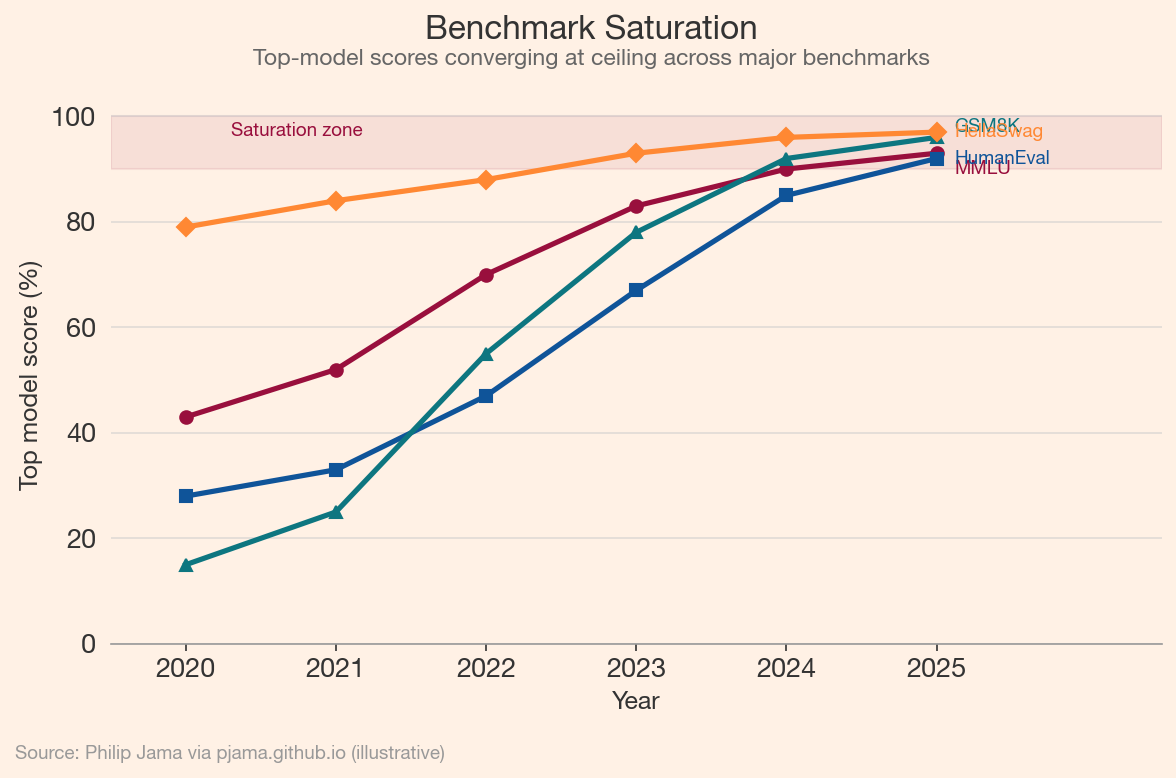
The emerging response is multi-dimensional: arena-style pairwise comparisons (Chatbot Arena), task-specific evaluations grounded in real workflows, and adversarial benchmarks designed to probe specific failure modes rather than average capability. Evaluation is becoming a discipline of its own rather than a reporting afterthought.
Models increasingly train on data generated by other models. The reasons are pragmatic: human-generated text of sufficient quality and diversity is finite, while model-generated data can be produced at arbitrary scale. Synthetic data is used for instruction tuning (generating diverse prompts and responses), reasoning traces (producing step-by-step solutions for math and code), and data augmentation (expanding small labeled datasets).
The risk is model collapse: when models train on their own outputs across generations, distributional tails thin and rare knowledge erodes. Shumailov et al. (2023) demonstrated this in controlled settings, showing progressive quality degradation over iterative self-training. The practical question is whether curation, filtering, and mixing synthetic data with fresh human-generated data can prevent this degradation at scale.
The economics of synthetic data also shift the competitive landscape. Organizations with access to strong models can generate high-quality training data for weaker models, creating a recursive improvement cycle. This dynamic partially explains why open-model capability has converged so rapidly with closed-model capability: distillation and synthetic data generation transfer knowledge across the model ecosystem.
Open-weight models (Llama, Mistral, Gemma, Qwen, DeepSeek) have compressed the capability gap with closed-model APIs from years to months. This is partly a consequence of the efficiency gains and synthetic data dynamics described above, and partly a strategic choice by organizations that benefit from ecosystem adoption over API revenue.
The economic implication: foundation model capability is commoditizing. When multiple open models achieve comparable quality on standard tasks, competitive advantage shifts to data (proprietary corpora and domain expertise), fine-tuning (adapting models to specific workflows, as covered in Alignment and Adaptation), and application integration (embedding models into products where the model is a component, not the product). The infrastructure layer (vector databases, orchestration frameworks, evaluation tooling) captures value as a complement to commoditized model capability.
The EU AI Act (enacted 2024) introduced risk-based classification for AI systems, with the most stringent requirements (transparency, conformity assessment, human oversight) applying to high-risk applications in healthcare, employment, law enforcement, and critical infrastructure. Foundation model providers face additional obligations around training data documentation, energy reporting, and safety evaluation.
In the United States, executive orders and agency guidance have outlined voluntary frameworks without the force of law. China's regulatory approach addresses specific applications (deepfakes, recommendation algorithms, generative AI) through targeted regulations rather than comprehensive legislation. The tension between innovation speed and regulatory response time is structural: models that take months to develop may take years to regulate.
The practical consequence for organizations deploying language technology is uncertainty: building for compliance with regulations that are still being written. The organizations best positioned are those treating safety, documentation, and evaluation not as compliance burdens but as engineering disciplines integrated into the development lifecycle.
The capabilities that have improved most dramatically (fluent generation, broad knowledge, code writing, instruction following) share a common property: they can be evaluated against clear reference signals. The capabilities that remain persistently difficult are those where evaluation is ambiguous and feedback signals are sparse.
Reliable reasoning over novel problems still degrades when the problem structure departs significantly from the training distribution. Calibrated uncertainty (knowing what the model does not know) remains weak; models express high confidence across correct and incorrect outputs alike. Long-horizon planning across dozens of interdependent steps accumulates errors in ways that current self-correction mechanisms cannot reliably address. Value alignment in contested domains, where reasonable people disagree about the right output, is a social problem as much as a technical one.
These are not shortcomings that scaling alone will resolve. They represent the next generation of bottlenecks, analogous to the sequential processing bottleneck that the transformer resolved. The architecture or technique that addresses them has not yet been identified.
The throughline across the history of NLP is a recurring pattern: each generation resolved a bottleneck, unlocked new capabilities, and revealed the next constraint. Rules could not handle ambiguity. Statistics could not capture semantics. Recurrent networks could not scale. The transformer resolved the scaling constraint and triggered an exponential expansion of capability that produced the systems we have today.
The current constraints are less architectural and more systemic: how to evaluate what these systems can and cannot do, how to deploy them safely in high-stakes domains, how to distribute their capabilities broadly without concentrating risk, and how to maintain human agency as the systems become more capable. These are not problems that admit purely technical solutions. The next chapter of language technology will be written at the intersection of engineering, economics, and governance.
If you're exploring related work and need hands-on help, I'm open to consulting and advisory. Get in touch›