Fidelity in LLM Information Processing
Preserving source signal through summarization, compression, and context engineering
LLMContext EngineeringInformation TheoryRAGPython
LLMContext EngineeringInformation TheoryRAGPython
In audio engineering, fidelity measures how faithfully a system reproduces its input signal. A high-fidelity amplifier preserves the source recording; a low-fidelity one introduces distortion, clips peaks, and loses detail. The same concept applies whenever information passes through a processing chain -- including the chains we build with large language models.
Every time we summarize a document, compress context to fit a token budget, or pass one model's output as the next model's input, we perform a signal processing operation. Some operations are nearly lossless. Others silently degrade the source in ways that compound across steps. The engineering discipline is the same one audio engineers practice: understand where fidelity loss occurs, measure it, and design systems that preserve the signal that matters.
This article treats context as signal. We examine how information degrades through LLM processing, identify the failure modes, and develop practical strategies for preserving source fidelity across summarization, retrieval, and multi-step pipelines.
Summarization is lossy compression. Unlike ZIP or gzip, there is no decompression step that recovers the original. Each summarization pass discards information permanently -- and the model chooses what to discard based on statistical patterns, not on what downstream tasks need.
The failure modes are predictable. Numerical precision loss: "revenue grew 12.3% year-over-year" becomes "revenue grew significantly." Attribution erasure: findings get separated from their sources, so "according to the Q3 audit" collapses into an ungrounded claim. Conditional nuance collapse: "effective for users with >1000 daily active sessions, but harmful below that threshold" becomes "effective for large-scale users." Each mode represents a different kind of signal degradation, and each compounds when summaries are summarized again.
Multi-hop reasoning chains pass one model's output as the next model's input. Each hop introduces small distortions: a rewording that shifts emphasis, a simplification that drops a qualifier, a confident restatement of something the source hedged. Over three or four hops, these distortions accumulate into drift -- the output diverges from the original source in ways no single step makes obvious.
The parallel is the telephone game. Each participant faithfully relays what they heard, yet the message at the end bears little resemblance to the original. The per-step error is small; the accumulated error is not. Any pipeline where LLM outputs feed into LLM inputs faces this compounding degradation.
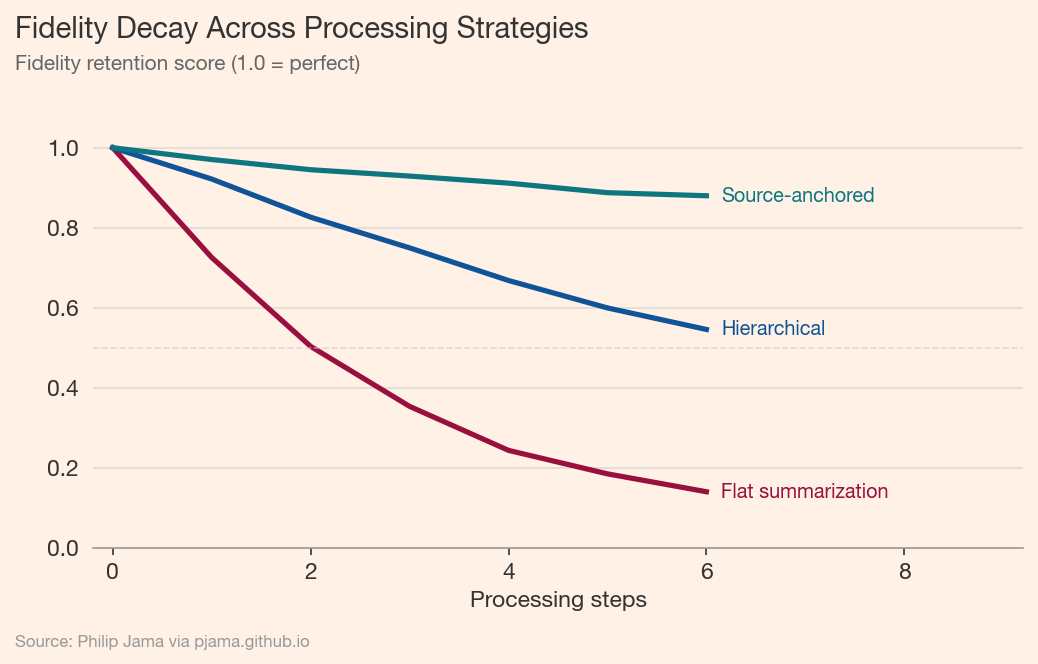
The following visualization compares three processing strategies across multiple steps. Flat summarization -- where each step compresses the previous output -- shows steep fidelity decay. Hierarchical approaches, which maintain multiple levels of detail, degrade more slowly. Source-anchored strategies, which re-consult the original at each step, remain nearly flat.
A context window is a communication channel with finite bandwidth. Every token spent on irrelevant context is noise that dilutes the signal. Packing 128k tokens with marginally relevant documents does not give the model more information -- it gives it more noise to filter, lowering the signal-to-noise ratio of the entire prompt.
The analogy to Shannon's channel capacity is direct. A channel has a maximum rate at which information can be reliably transmitted. Exceeding that rate does not increase throughput; it increases errors. Similarly, stuffing a context window past the point of useful information does not improve output quality -- it degrades it. The model's attention becomes a scarce resource spread across too many tokens.
Prompt construction faces the classic precision-recall tradeoff. High precision (only the most relevant chunks) risks missing context the model needs. High recall (include everything plausibly related) floods the window with noise. Neither extreme produces high-fidelity output.
The resolution is tiered context: full source text for high-relevance documents, structured summaries for supporting material, and exclusion of the rest. This mirrors how human analysts work -- reading primary sources in full while consulting summaries of background material. The tiers are an explicit bandwidth allocation: spend tokens where they carry the most signal.
Facts that carry inline provenance survive summarization better than naked claims. "Revenue grew 12.3% (Source: Q3 Report, Table 2)" is harder for a summarizer to reduce to "revenue grew significantly" because the attribution signals precision. Embedding provenance directly in content -- rather than in footnotes or metadata -- keeps it in the signal path where the model processes it.
This is a form of redundant encoding. The source tag carries no new information about revenue, but it encodes a constraint: this number has a specific origin and should be preserved exactly. Structured attribution raises the cost of lossy compression by making the loss visible.
A single flat summary discards detail uniformly. Hierarchical summarization maintains multiple levels: a one-paragraph executive summary, a section-level summary with key figures, and the full source. Different tasks draw from different levels. A routing question needs only the top level; a fact-checking task needs the full source.
This maps directly to the multi-level retrieval strategy in GraphRAG, where community summaries at different granularities serve different query types. The principle is the same: preserve multiple resolutions of the signal rather than committing to a single lossy compression.
Chain-of-thought prompting is often framed as a reasoning improvement. It also serves as a fidelity strategy. When a model shows its intermediate steps, each step is inspectable -- we can verify that the source signal survived the transformation. Hidden reasoning hides errors. If a model jumps from source document to conclusion without visible intermediate steps, there is no way to detect where fidelity loss occurred.
The tradeoff is token cost. Showing work consumes context window bandwidth. But the tokens spent on chain-of-thought are signal -- they make the processing chain transparent and auditable. This is a bandwidth allocation decision, not waste.
Retrieval-augmented generation restores fidelity by re-consulting the source rather than relying on degraded copies. Each retrieval step refreshes the context with original-fidelity content, resetting the drift that accumulates through summarization chains. This is why RAG pipelines often outperform systems that pre-summarize their knowledge base: they trade compute for fidelity.
The knowledge graph approaches in Knowledge Graphs from Text and GraphRAG extend this principle. Structured extraction preserves entity relationships and provenance that flat text retrieval might miss. The graph is a fidelity-preserving representation -- it captures the relational structure of the source, not just its surface text.
When specific facts must survive a processing step verbatim, name them explicitly in the prompt. "The following numbers must appear unchanged in your output: 12.3% revenue growth, $4.2M ARR, 847 enterprise accounts." This is invariant specification for LLM pipelines -- the same discipline as writing assertions in software, applied to information processing.
Preservation contracts work because they convert implicit expectations into explicit constraints. Without them, the model optimizes for fluency and coherence, which may conflict with numerical precision. With them, the model has a clear signal about what the consumer of its output needs preserved.
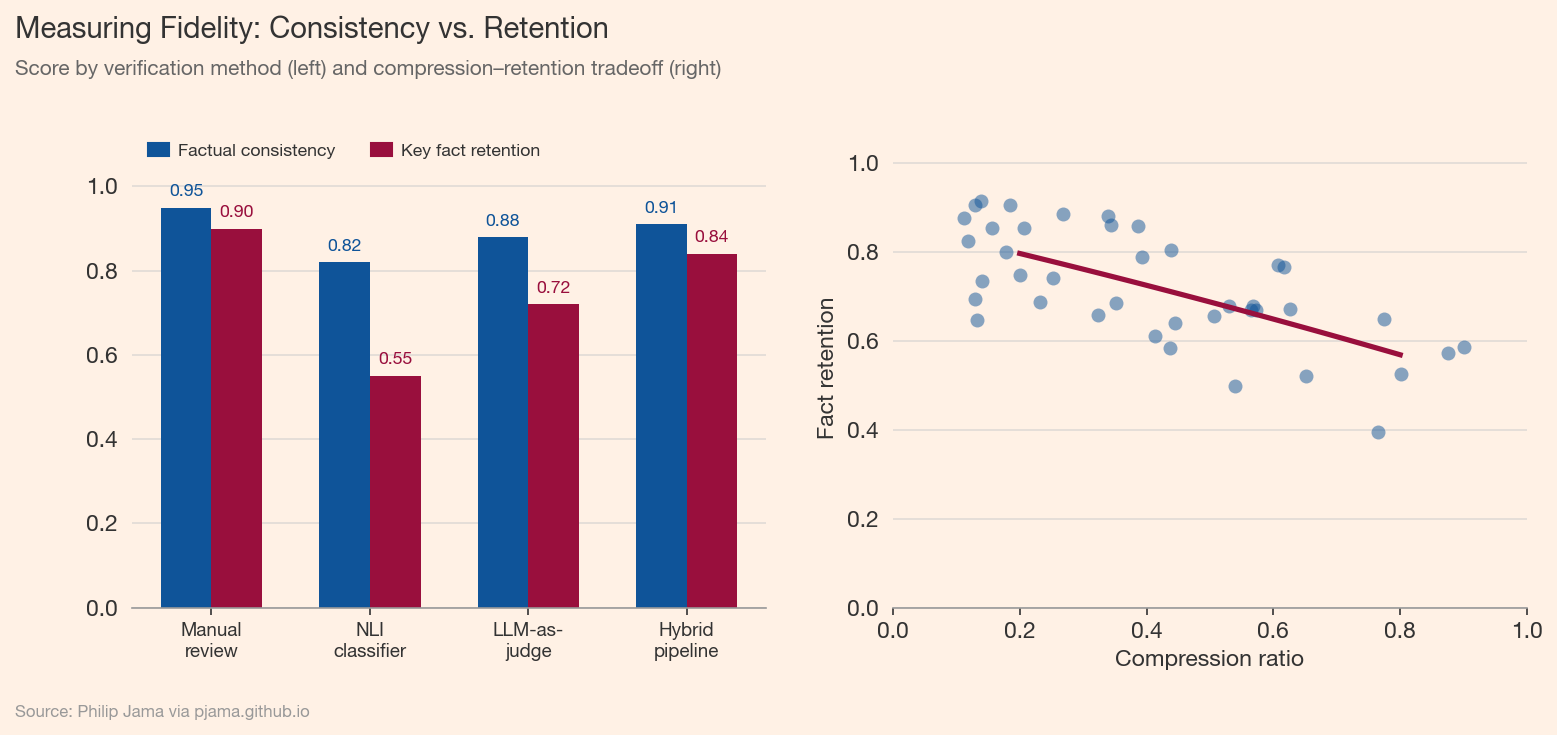
Fidelity measurement compares output against source. Three approaches, in order of increasing automation: manual review against source documents, natural language inference (NLI) models that classify output sentences as entailed, contradicted, or neutral relative to the source, and LLM-as-judge evaluation where a separate model checks faithfulness. Each trades cost for coverage.
The NLI approach is attractive for pipeline monitoring: run every output through an entailment classifier and flag contradictions automatically. But entailment checks only catch one class of fidelity failure -- they detect when the output says something the source does not support. They do not detect when the output omits something the source says.
Detecting additions (hallucination) is easier than detecting omissions. A contradicted claim triggers NLI classifiers and fact-checkers. A missing fact triggers nothing. Yet a technically accurate summary that omits the key finding is a fidelity failure no contradiction check catches.
This asymmetry means that fidelity measurement must include recall-oriented checks: does the output contain the critical facts from the source? This requires defining what "critical" means up front -- another argument for explicit preservation contracts. Without a specification of what must survive, there is no way to measure whether it did.
The following visualization compares factual consistency (contradiction detection) against key fact retention (recall) across processing methods, and shows the relationship between compression ratio and fact retention.
High-fidelity systems maintain a source-of-truth layer: canonical data that is never summarized away. Summaries are caches, not replacements. When a downstream process needs precision, it queries the source layer directly. When it needs speed or breadth, it reads from the summary cache.
The parallel to database normalization is direct. A normalized schema stores each fact once and derives views as needed. Denormalized caches trade fidelity for performance. The same tradeoff applies to LLM pipelines: pre-computed summaries are denormalized caches of the source documents. Treat them accordingly -- use them for routing and overview, not for precision tasks.
A practical implementation uses three tiers. Tier 1: full source text for the most relevant documents. Tier 2: structured summaries (with key figures and source attribution) for supporting context. Tier 3: metadata and routing information (titles, dates, relevance scores) for everything else. The tier is selected by task type and relevance score.
This maps to the local vs. global retrieval distinction in GraphRAG. Local queries need Tier 1 (specific passages from specific documents). Global queries need Tier 2 (community summaries that span the corpus). Routing queries need only Tier 3. Matching the tier to the task prevents both fidelity loss (from over-compression) and noise (from under-filtering).
Every derived artifact should record its derivation chain: which source documents contributed, what prompt produced it, which model version ran, and when. This is version control for information processing. When a source document updates, we can identify which downstream artifacts are stale and re-derive them.
The knowledge graph approach in LLM Knowledge Graphs provides a natural structure for provenance tracking. Entities and relationships extracted from source documents carry their source attribution as graph metadata. When the source changes, the affected subgraph is identifiable and can be selectively refreshed.
Cache invalidation is a fidelity management decision. Re-derive when the source document has changed, when the task requires numerical precision, or when the cached artifact is multiple hops from the original. Cache when the source is stable, the task tolerates approximation, and the derivation is expensive.
A useful heuristic: count the hops between the cached artifact and its source. One hop (direct summary) is usually safe to cache. Two hops (summary of summaries) warrants periodic re-derivation. Three or more hops should trigger re-derivation from source for any precision-sensitive task. The hop count is a proxy for accumulated drift.
Larger context windows shift the engineering problem from "what fits" to "what matters." A 200k-token window does not eliminate fidelity concerns -- it changes them. The noise floor rises with context length, attention diffuses over more tokens, and the temptation to include everything replaces the discipline of selecting what is relevant. The signal engineering mindset -- measure what you need, preserve it deliberately, verify it survived -- remains the core discipline regardless of how many tokens the model can hold.
If you're exploring related work and need hands-on help, I'm open to consulting and advisory. Get in touch›