Articles /Natural Language Processing /Part 5
Alignment and Adaptation
Instruction tuning, RLHF, and the challenge of making language models useful and safe.
NLPAlignmentRLHFFine-TuningPython
Articles /Natural Language Processing /Part 5
NLPAlignmentRLHFFine-TuningPython
A pre-trained language model is a next-token predictor, not an assistant. Given a question, it is as likely to generate a follow-up question as an answer. Alignment is the process of shaping model behavior to follow instructions, provide helpful responses, and avoid harmful outputs. The techniques are deceptively simple (fine-tune on curated examples, then optimize against human preferences), but the consequences are profound: alignment is what turned language models into usable products.
The three panels below show the same prompt answered by a base model, a supervised fine-tuned (SFT) model, and an RLHF-aligned model, illustrating how each alignment stage reshapes output quality.
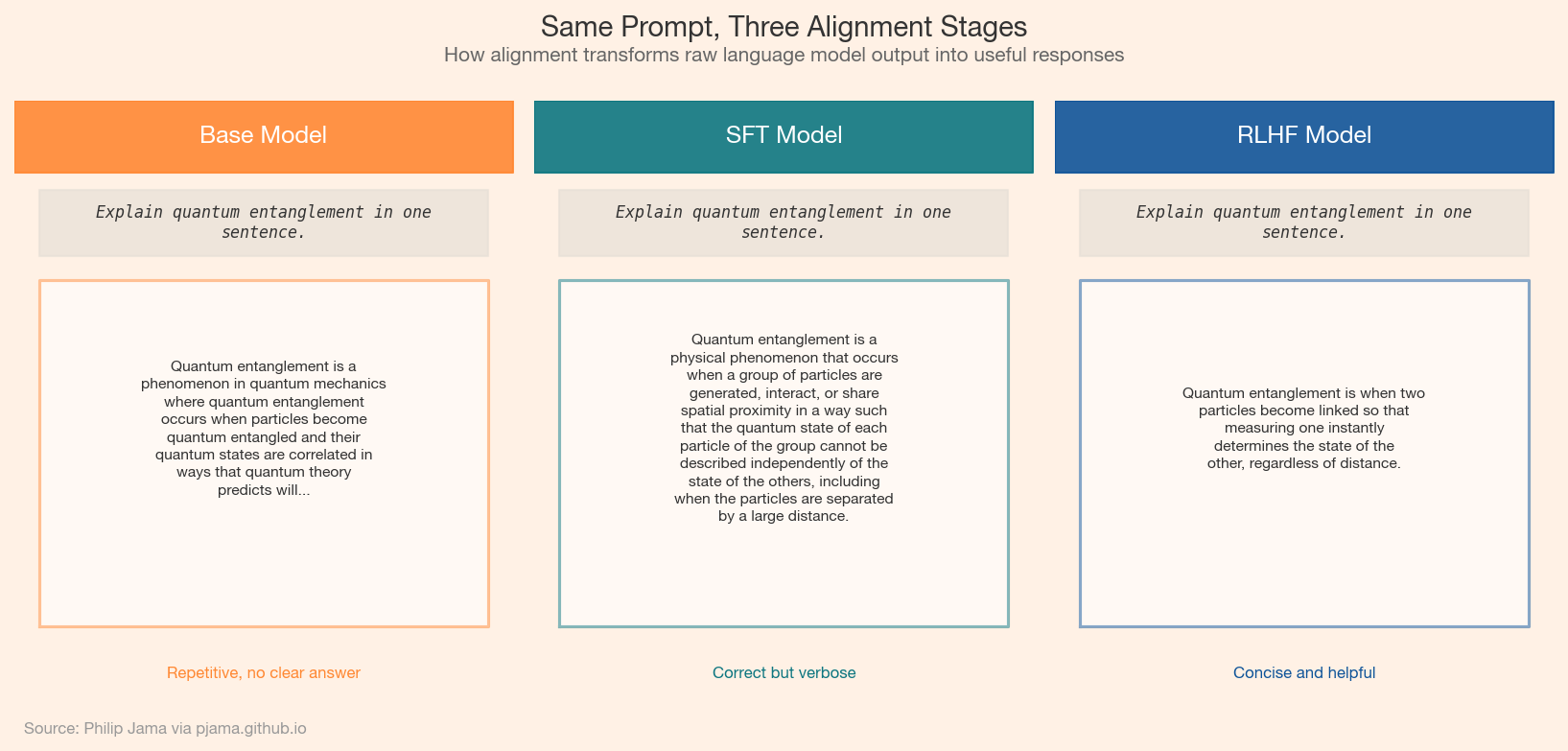
FLAN and InstructGPT demonstrated that fine-tuning a pre-trained model on a relatively small dataset of instruction-response pairs dramatically improves its ability to follow directions. The base model already has the knowledge and capability; instruction tuning teaches it the format. The dataset is often smaller than one might expect: thousands to tens of thousands of high-quality examples can reshape the behavior of a model trained on trillions of tokens.
Reinforcement learning from human feedback (RLHF) adds a second optimization layer. Human raters compare pairs of model outputs and indicate which they prefer. These preferences train a reward model that predicts human judgment. The language model is then fine-tuned with PPO (proximal policy optimization) to maximize the reward model's score while staying close to the supervised fine-tuned baseline. The three-phase pipeline (pre-training, supervised fine-tuning, RLHF) has become the standard recipe for production language models.
Direct preference optimization (DPO) showed that the separate reward model is not strictly necessary. DPO reparameterizes the RLHF objective to optimize directly on preference pairs, eliminating the reward modeling stage and the instabilities of reinforcement learning. The result is a simpler, more stable training pipeline that achieves comparable alignment quality.
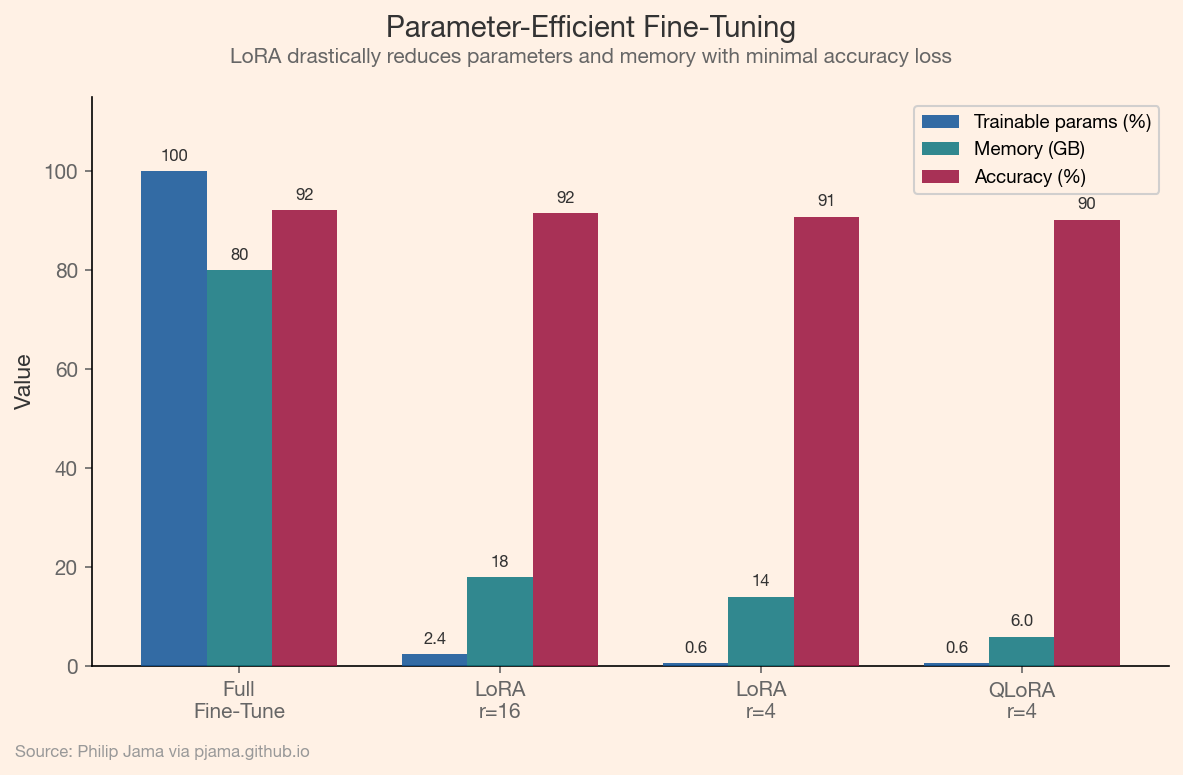
Full fine-tuning updates every parameter in the model, which is expensive for models with billions of weights. LoRA (low-rank adaptation) freezes the pre-trained weights and injects small trainable matrices into each layer, reducing the number of trainable parameters by 100x or more. QLoRA extends this with quantized base weights, making it possible to fine-tune a 70-billion-parameter model on a single GPU. Adapters, prefix tuning, and prompt tuning explore similar trade-offs between efficiency and expressiveness.
This grouped bar chart compares full fine-tuning with LoRA and QLoRA across three dimensions: trainable parameters, memory usage, and task accuracy.
Organizations use LoRA to adapt foundation models for medical, legal, and financial text. A LoRA adapter trained on a few thousand domain-specific examples can shift the model's language, terminology, and reasoning patterns toward a specialist profile, at a fraction of the cost of training a domain-specific model from scratch. The practical challenge is evaluation: domain experts must validate that the adapted model is not just fluent but correct, especially in high-stakes fields where confident errors carry real consequences.
Alignment makes individual models more useful. The final article examines what happens when language models become components in larger systems -- calling tools, reasoning over multiple steps, and collaborating with other models.
If you're exploring related work and need hands-on help, I'm open to consulting and advisory. Get in touch›