Articles /Natural Language Processing /Part 4
Embeddings, Retrieval, and RAG
Vector representations, semantic search, and grounding language models in external knowledge.
NLPRAGEmbeddingsVector SearchPython
Articles /Natural Language Processing /Part 4
NLPRAGEmbeddingsVector SearchPython
Language models encode knowledge in their parameters during pre-training. This parametric memory is powerful but has fundamental limits: it is frozen at training time, difficult to update, and prone to confident fabrication when the answer is not in the weights. Retrieval-augmented generation (RAG) addresses these limits by separating knowledge storage from reasoning: the model retrieves relevant documents at inference time and reasons over them in context.
Word2Vec and GloVe produced word-level embeddings. Modern embedding models (trained with contrastive learning objectives) produce dense vector representations for sentences and documents. These embeddings map semantic similarity to geometric proximity: texts about similar topics cluster together in high-dimensional space, and cosine similarity between vectors serves as a practical measure of semantic relatedness.
The scatter plot below shows synthetic document embeddings projected into two dimensions, colored by topic. The query point (star) connects to its nearest neighbors, illustrating how semantic search retrieves related documents.
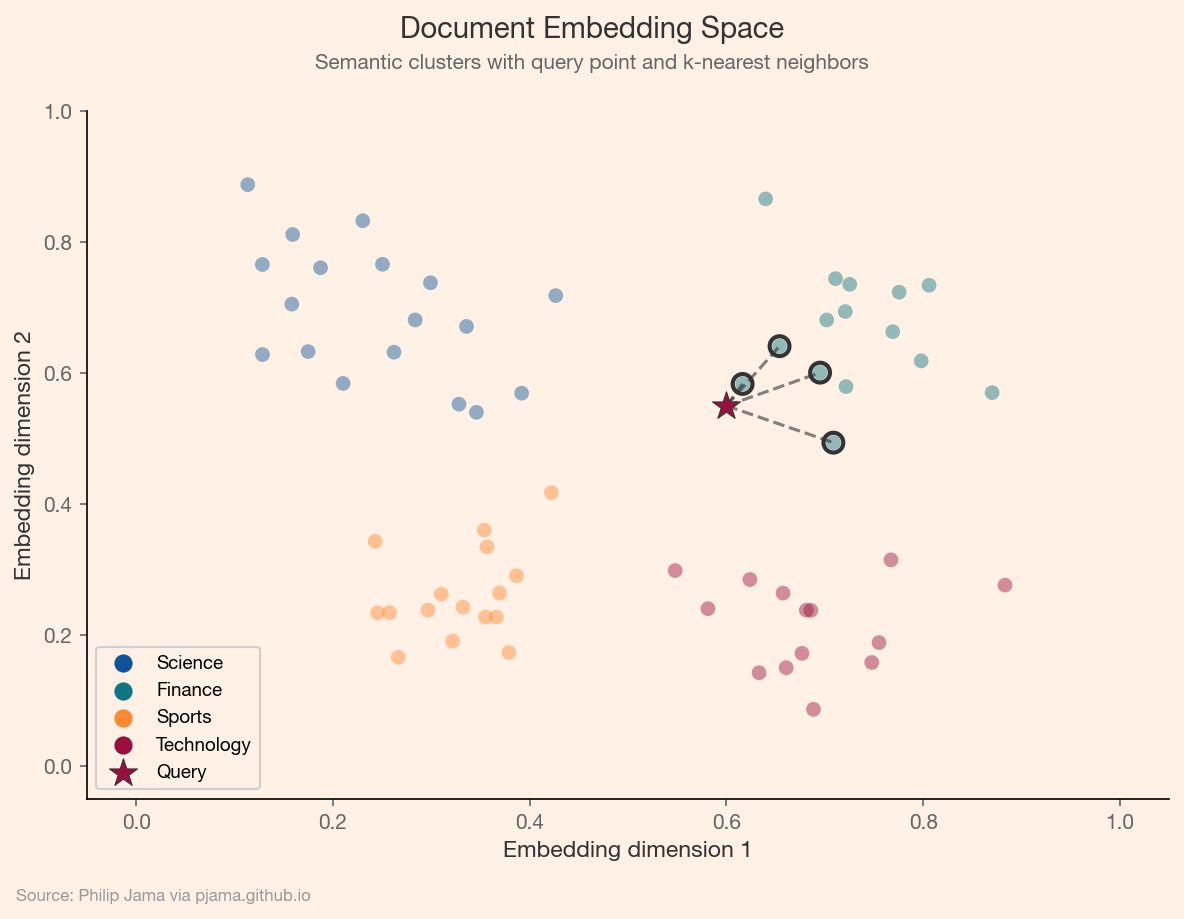
Exact nearest-neighbor search over millions of vectors is expensive. Approximate nearest-neighbor (ANN) algorithms such as HNSW, IVF, and product quantization trade a small accuracy loss for orders-of-magnitude speedup. Vector databases (Pinecone, Weaviate, Qdrant, pgvector) wrap these algorithms with indexing, filtering, and persistence, making semantic search a commodity infrastructure component.
The RAG pipeline has three stages: encode the query into an embedding, retrieve the top-k most similar chunks from a vector store, and assemble the retrieved text into the model's context window for generation. This separation of concerns (the retriever handles recall, the generator handles synthesis) means knowledge can be updated by re-indexing documents without retraining the model.
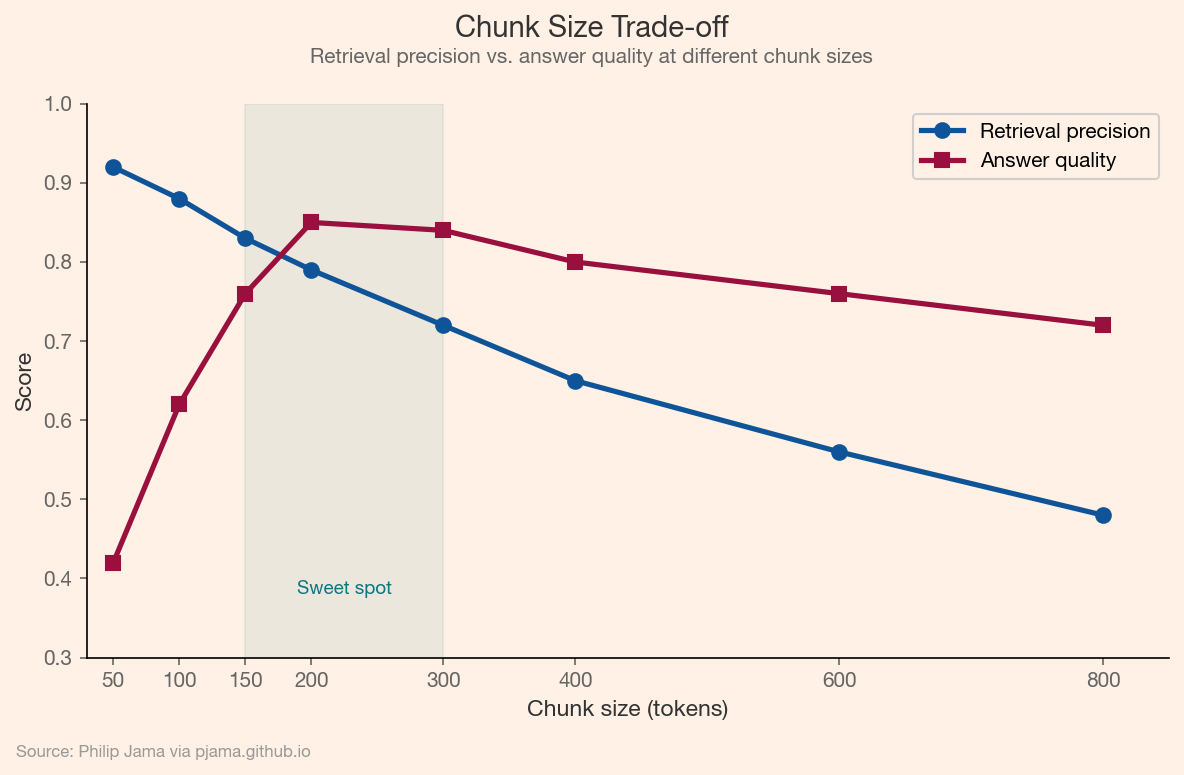
How documents are split into chunks determines retrieval quality. Small chunks (100--200 tokens) enable precise retrieval but lose surrounding context. Large chunks (500--1000 tokens) preserve context but dilute relevance. Overlapping windows, hierarchical chunking, and parent-document retrieval are strategies for managing this trade-off. The right chunking strategy depends on the document type and the kinds of questions the system needs to answer.
The following chart illustrates the tension between retrieval precision and answer quality as chunk size varies, with a sweet spot in the 150–300 token range.
For a deeper treatment of how information degrades across processing stages (summarization, chunking, and multi-hop retrieval), see Fidelity in LLM Information Processing. For graph-structured retrieval as an alternative to flat chunking, see GraphRAG.
RAG made it practical to build Q&A systems over proprietary documents without fine-tuning a model on internal data. Customer support teams, legal departments, and engineering organizations use RAG to surface answers from policy manuals, case law, and internal documentation. The production challenges are less about the model and more about retrieval: ensuring the right chunks surface for a given question, handling documents that update frequently, and managing the quality feedback loop between retrieval precision and answer accuracy.
RAG improves factual grounding, but the model's behavior itself matters. The next article examines how fine-tuning and alignment shape what language models do with the knowledge they have.
If you're exploring related work and need hands-on help, I'm open to consulting and advisory. Get in touch›