Articles /Natural Language Processing /Part 1
From Rule-Based NLP to the Transformer
Fifty years of language processing, the bottlenecks each generation left behind, and the architecture that resolved them.
NLPTransformersDeep LearningPython
Articles /Natural Language Processing /Part 1
NLPTransformersDeep LearningPython
Language is ambiguous, context-dependent, and vast. Every generation of NLP attacked the problem differently, and each left a characteristic bottleneck for the next to resolve. Formal grammars could not handle ambiguity. Statistical methods could not capture long-range context. Recurrent networks captured context but processed it sequentially, creating a computational wall that limited both training scale and representational depth.
The transformer architecture (Vaswani et al., 2017) removed the sequential bottleneck entirely. Self-attention lets every token attend to every other token simultaneously, trading O(n) sequential steps for O(1) depth at the cost of O(n²) memory. That trade-off turned out to be decisive: it unlocked parallelization across hardware, which unlocked training on vastly more data, which unlocked capabilities no one anticipated.
Chomsky's formal grammars (1950s–1980s) treated language as a rule-governed system. Parse trees, context-free grammars, and hand-crafted rules worked for constrained domains but collapsed under the weight of real-world ambiguity. Every exception required a new rule, and the combinatorial explosion of natural language made complete coverage impossible.
The 1990s replaced hand-crafted rules with probabilities learned from data. N-gram models, TF-IDF representations, and classifiers like naive Bayes made NLP tractable for tasks such as spam filtering and document classification. The bottleneck shifted: statistical models treated words as atomic symbols with no notion of similarity. "Dog" and "puppy" were as unrelated as "dog" and "mortgage."
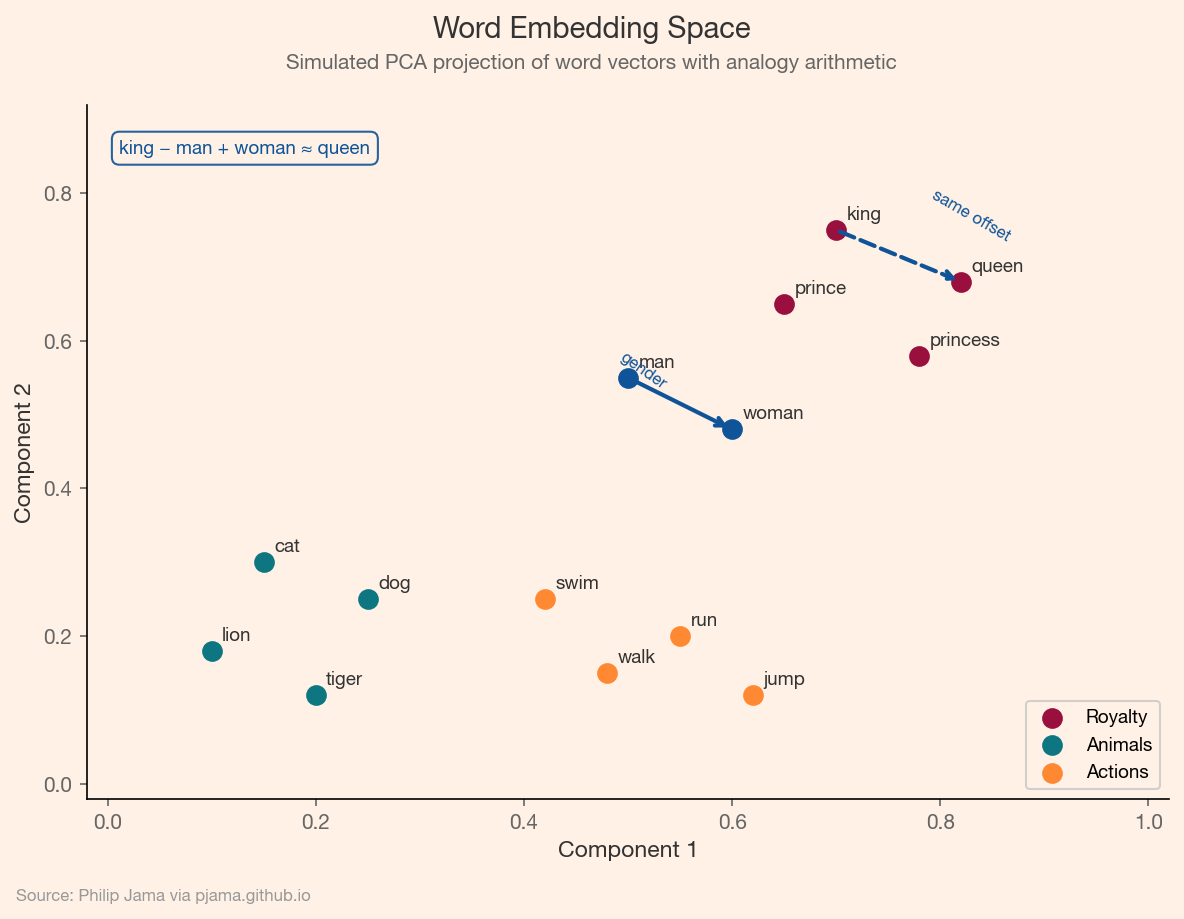
"You shall know a word by the company it keeps" (Firth, 1957). Word2Vec and GloVe operationalized this insight by learning dense vector representations (embeddings) where semantic similarity mapped to geometric proximity. The king–queen analogy (king - man + woman ≈ queen) demonstrated that these vectors captured relational structure, not just co-occurrence statistics.
The following visualization shows a simulated PCA projection of word embeddings, with semantic clusters for royalty, animals, and actions, and the classic king–queen analogy as vector arithmetic.
Recurrent neural networks (RNNs) and their gated variants (LSTMs, GRUs) processed sequences token by token, maintaining a hidden state that carried forward context. This worked for short sequences but degraded over longer ones; the vanishing gradient problem made it difficult to connect information across distant positions. Encoder-decoder architectures with Bahdanau attention partially addressed this by letting the decoder attend to specific encoder states, but the fundamental sequential bottleneck remained.
Self-attention computes queries, keys, and values for every token and uses their dot products to determine how much each token attends to every other. Multi-head attention runs this operation in parallel across multiple learned subspaces, letting the model capture different types of relationships simultaneously. Positional encodings inject sequence order into an architecture that is otherwise permutation-invariant.
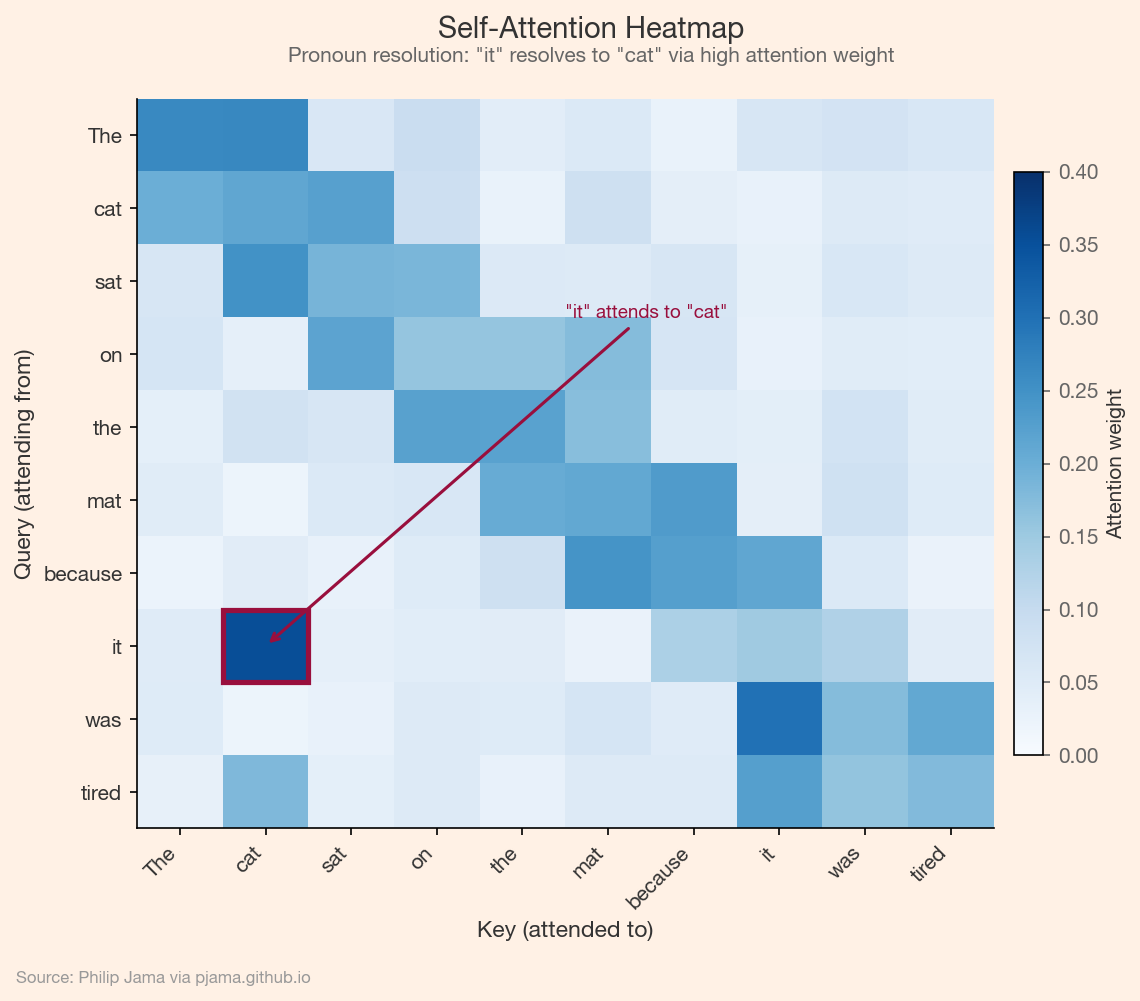
This heatmap shows synthetic self-attention weights for a short sentence, illustrating how the pronoun "it" attends strongly to its antecedent "cat."
The computational trade-off (constant depth for quadratic memory) was exactly right for modern hardware. GPUs and TPUs excel at large matrix multiplications, and self-attention is a matrix multiplication. The result: transformers trained on more data, faster, than any previous architecture.
Machine translation traces the full arc. Rule-based MT systems required hand-built bilingual dictionaries and transfer rules. Statistical MT (phrase-based models) improved quality but struggled with long-range reordering. Neural MT with RNNs and attention produced fluent output but trained slowly. Google's 2016 neural pivot, replacing their phrase-based system with an attention-based encoder-decoder, marked the inflection point. The transformer, developed for translation, turned out to be the foundation for everything that followed.
The transformer was a general-purpose architecture. The next article examines the two divergent strategies for training it, and how each unlocked different capabilities.
If you're exploring related work and need hands-on help, I'm open to consulting and advisory. Get in touch›