Articles /Natural Language Processing /Part 2
Pre-training and the BERT/GPT Divergence
Masked language modeling, autoregressive generation, and the transfer learning paradigm.
NLPBERTGPTTransfer LearningPython
Articles /Natural Language Processing /Part 2
NLPBERTGPTTransfer LearningPython
The transformer gave NLP a powerful architecture. The pre-training revolution gave it a powerful training strategy: learn general language representations from vast unlabeled text, then fine-tune on small task-specific datasets. This changed the economics of NLP. A single pre-trained model replaced dozens of task-specific architectures, and teams with limited labeled data could achieve state-of-the-art results by standing on the shoulders of unsupervised pre-training.
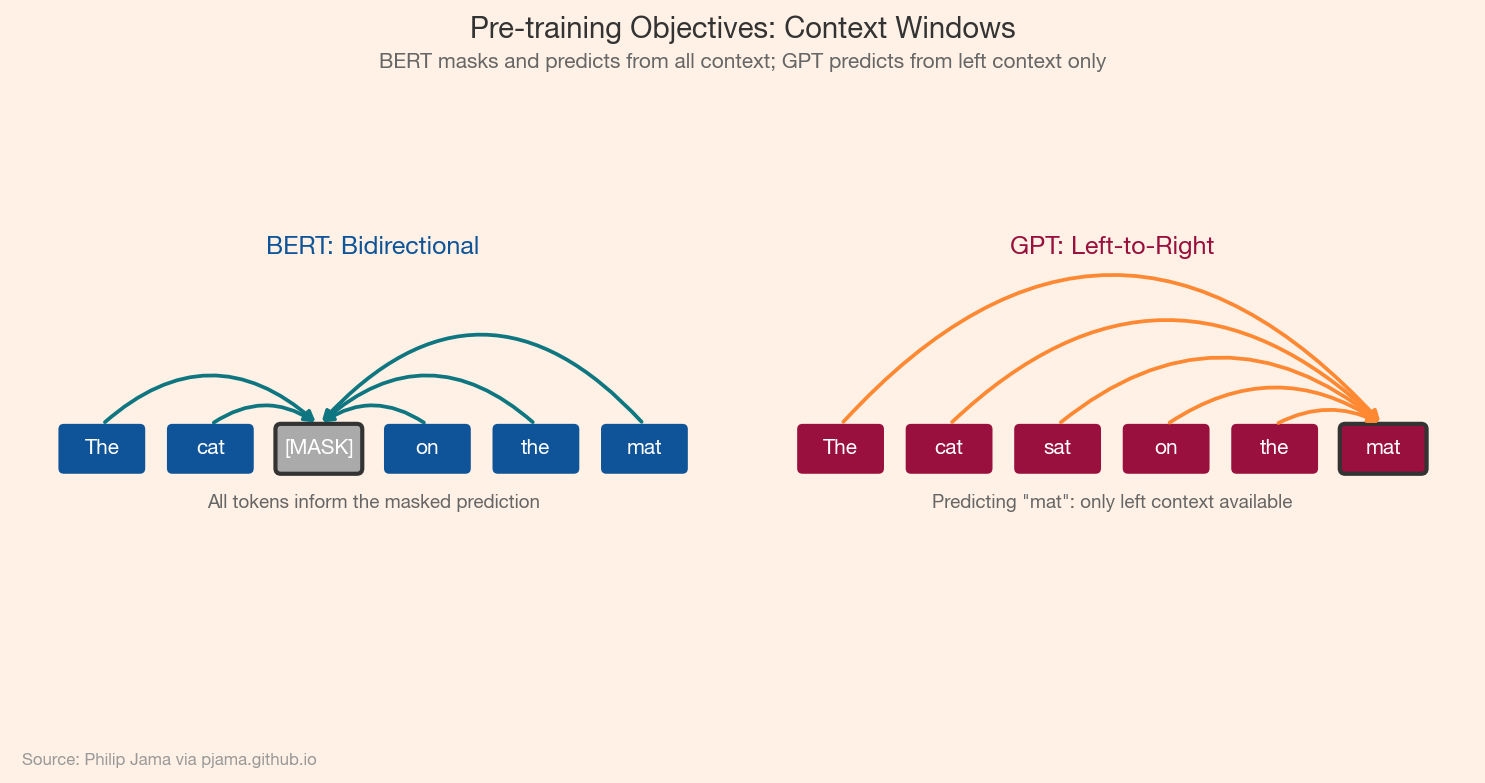
Two divergent pre-training objectives emerged, each producing fundamentally different capabilities. BERT masked tokens and predicted them from bidirectional context, optimized for understanding. GPT predicted the next token from left-to-right context, optimized for generation. The choice of objective was not a minor implementation detail; it determined what each model family could and could not do well.
BERT (Devlin et al., 2018) randomly masks 15% of input tokens and trains the model to reconstruct them. Because prediction flows from both left and right context simultaneously, the resulting representations encode bidirectional understanding. This made BERT a natural fit for classification, named entity recognition, and question answering: tasks where the full input is available at inference time.
GPT (Radford et al., 2018) predicts each token from the tokens that precede it. The model never sees future context during training, which means it learns to generate coherent continuations. This left-to-right constraint is a limitation for understanding tasks but aligns naturally with text generation: the model produces output one token at a time, each conditioned on everything before it.
The following diagram contrasts the two pre-training strategies: BERT sees bidirectional context around a masked token, while GPT sees only the tokens to the left.
Transfer learning from pre-trained models collapsed NLP leaderboards. GLUE and SuperGLUE benchmarks, designed to be challenging multi-task evaluations, were saturated within months of BERT's release. The pattern was consistent: pre-train once on a large corpus, then fine-tune with a small task-specific head and a few thousand labeled examples. RoBERTa, ALBERT, XLNet, and T5 explored variations on the theme (different masking strategies, different architectures, different pre-training data), but the core insight held: unsupervised pre-training on text is a remarkably effective initialization.
This chart illustrates the data efficiency advantage of transfer learning: a fine-tuned pre-trained model reaches high accuracy with a fraction of the labeled data required when training from scratch.
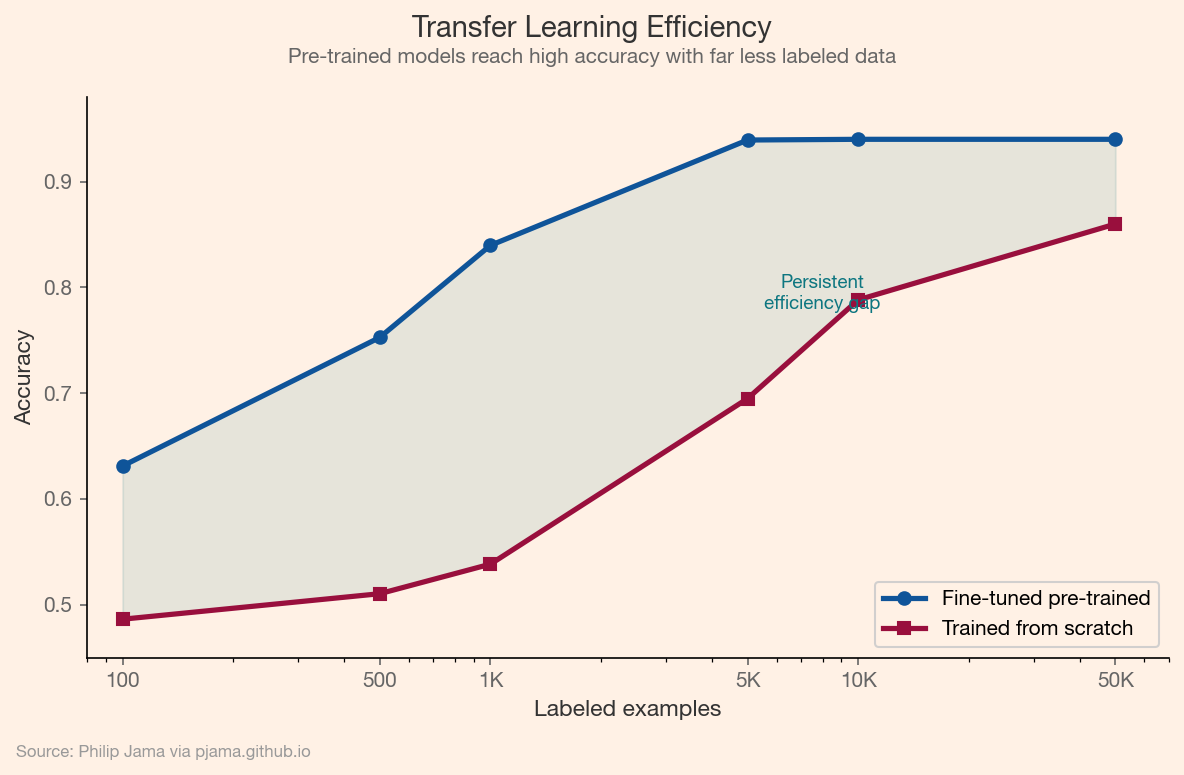
Sentiment analysis and content moderation illustrate the practical impact. Before BERT, production systems relied on hand-crafted feature engineering: sentiment lexicons, POS tag patterns, and domain-specific rules. A fine-tuned BERT model trained on a few thousand labeled examples outperformed years of manual feature work. This made it practical to classify text at scale (flagging toxic content, routing support tickets, gauging customer sentiment) with a fraction of the engineering effort previously required.
Pre-training worked better than anyone expected. The next article examines what happened when researchers asked: what if we just made these models bigger?
If you're exploring related work and need hands-on help, I'm open to consulting and advisory. Get in touch›