Articles /Natural Language Processing /Part 3
Scaling Laws and Emergent Abilities
What happens when language models grow by orders of magnitude.
NLPLLMScaling LawsEmergencePython
Articles /Natural Language Processing /Part 3
NLPLLMScaling LawsEmergencePython
Pre-training worked. The next question was straightforward: what happens if we make the models bigger, train them on more data, and use more compute? The answer turned out to be surprisingly predictable in some ways and deeply surprising in others. Loss follows smooth power-law curves as compute increases, but capabilities emerge in discontinuous jumps.
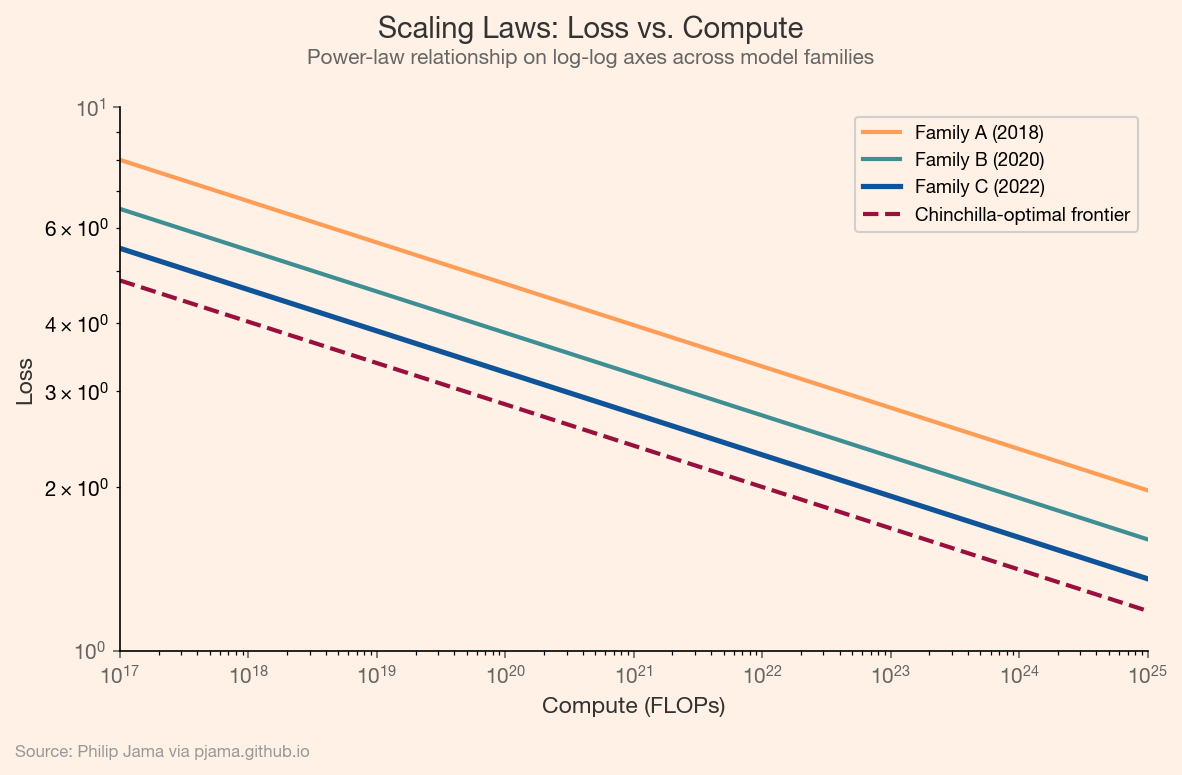
Kaplan et al. (2020) demonstrated that language model loss follows a power-law relationship with compute, dataset size, and parameter count. Double the compute, and loss decreases by a predictable amount. This relationship holds across orders of magnitude, making it possible to predict the performance of larger models before training them. Hoffmann et al. (2022) refined this with the Chinchilla result: for a fixed compute budget, there is an optimal ratio of parameters to training tokens. Many earlier models were undertrained relative to their size.
The following plot shows the power-law relationship between compute and loss on log-log axes, with a Chinchilla-optimal frontier marking the efficient allocation of compute to parameters and data.
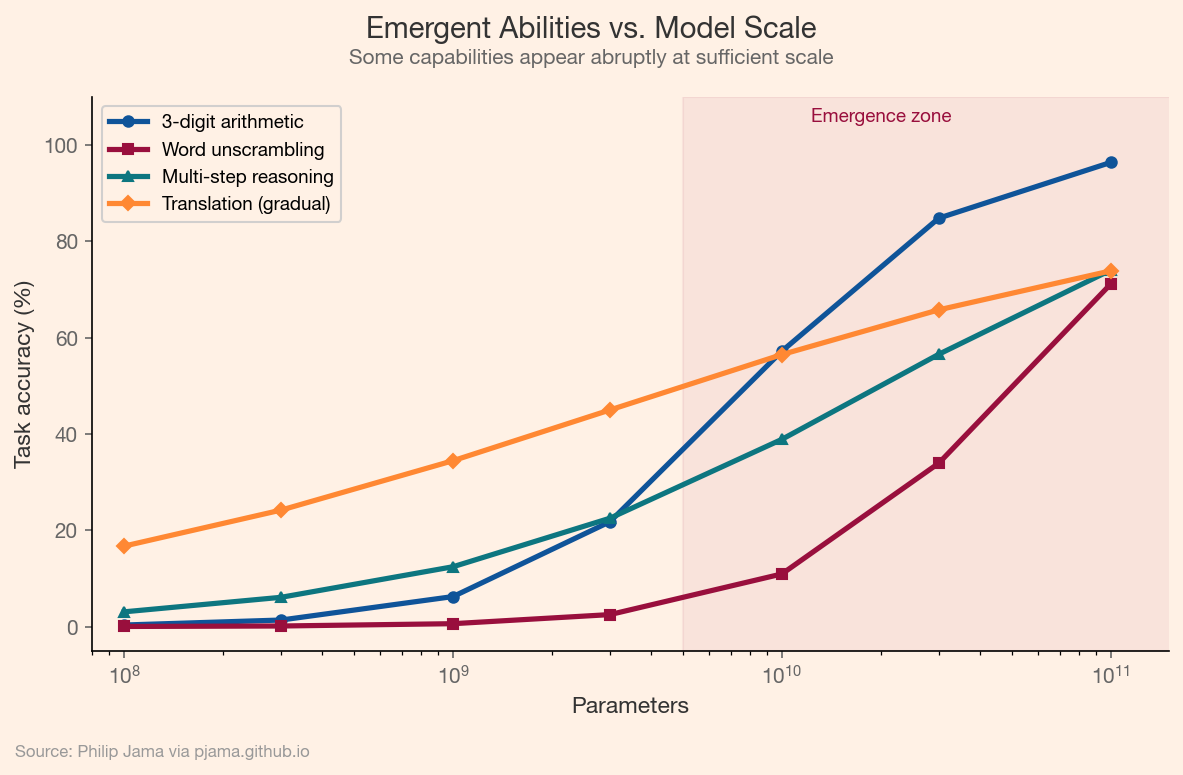
Some capabilities appear only at sufficient scale. Arithmetic, multi-step reasoning, and code generation are near-absent in small models but emerge (sometimes abruptly) as models grow. The phase-transition metaphor is apt: smooth scaling curves in loss coexist with step-function jumps in task accuracy. Whether these transitions are genuine discontinuities or measurement artifacts of threshold-based evaluation remains debated, but the practical effect is clear: scale unlocks qualitatively new behavior.
This chart plots task accuracy against model scale for several capabilities, showing how some tasks exhibit abrupt emergence while others improve gradually.
Large models can learn from examples provided in the prompt, without any weight updates. In-context learning and few-shot prompting let users demonstrate a task with a handful of examples and receive correct outputs on new inputs. This is not fine-tuning; the model's parameters do not change. The mechanism is not fully understood, but the practical consequence is significant: deploying NLP on a new task no longer requires collecting training data or running a training loop.
Prompting a model to "think step by step" before answering (chain-of-thought prompting) unlocks performance on tasks that benefit from intermediate reasoning. Arithmetic, word problems, and logical puzzles all improve substantially when the model generates reasoning traces rather than jumping directly to an answer. The technique is simple but reveals something important: the model has latent capabilities that the right prompt can surface.
In-context learning changed enterprise NLP deployment. Contract clause extraction, support ticket routing, and compliance classification (tasks that previously required months of labeled data collection and model training) can now be addressed with a well-constructed prompt containing a few representative examples. The trade-off is cost per inference versus cost of data collection, and for many low-volume, high-value tasks, in-context learning wins decisively.
Large language models encode vast knowledge in their parameters, but parametric memory has limits. The next article examines how retrieval systems ground language models in external knowledge.
If you're exploring related work and need hands-on help, I'm open to consulting and advisory. Get in touch›