The Secretary Problem and Optimal Stopping
When to stop looking and commit: the 37% rule and beyond
Decision ScienceOptimal StoppingProbabilityPython
Decision ScienceOptimal StoppingProbabilityPython
You're hiring for a critical role. Candidates arrive one at a time, you can rank them against those you've already seen, but once you reject someone they're gone forever. How do you maximize your chance of picking the best? This is the secretary problem: one of the most elegant results in probability and decision theory. The optimal strategy is surprisingly simple: observe the first ~37% of candidates without hiring anyone, then immediately hire the next candidate who is better than all those you've seen.
The problem has clean assumptions:
n candidates, arriving in random order.Under these rules, a naive strategy (pick randomly) gives you a 1/n chance of getting the best. The optimal strategy does dramatically better.
The optimal strategy is a look-then-leap rule:
r candidates and reject them all, but track the best score seen.r+1 onward, hire the first person who beats every candidate in the look phase.The optimal cutoff r is approximately n/e (where e ≈ 2.718), which means you should observe about 37% of the pool before switching to selection mode. With this strategy, you select the best candidate with probability ~1/e ≈ 0.368 -- regardless of how large n is. That's a striking result: even with 1,000 candidates, you have a 37% chance of picking the absolute best by using this simple rule.
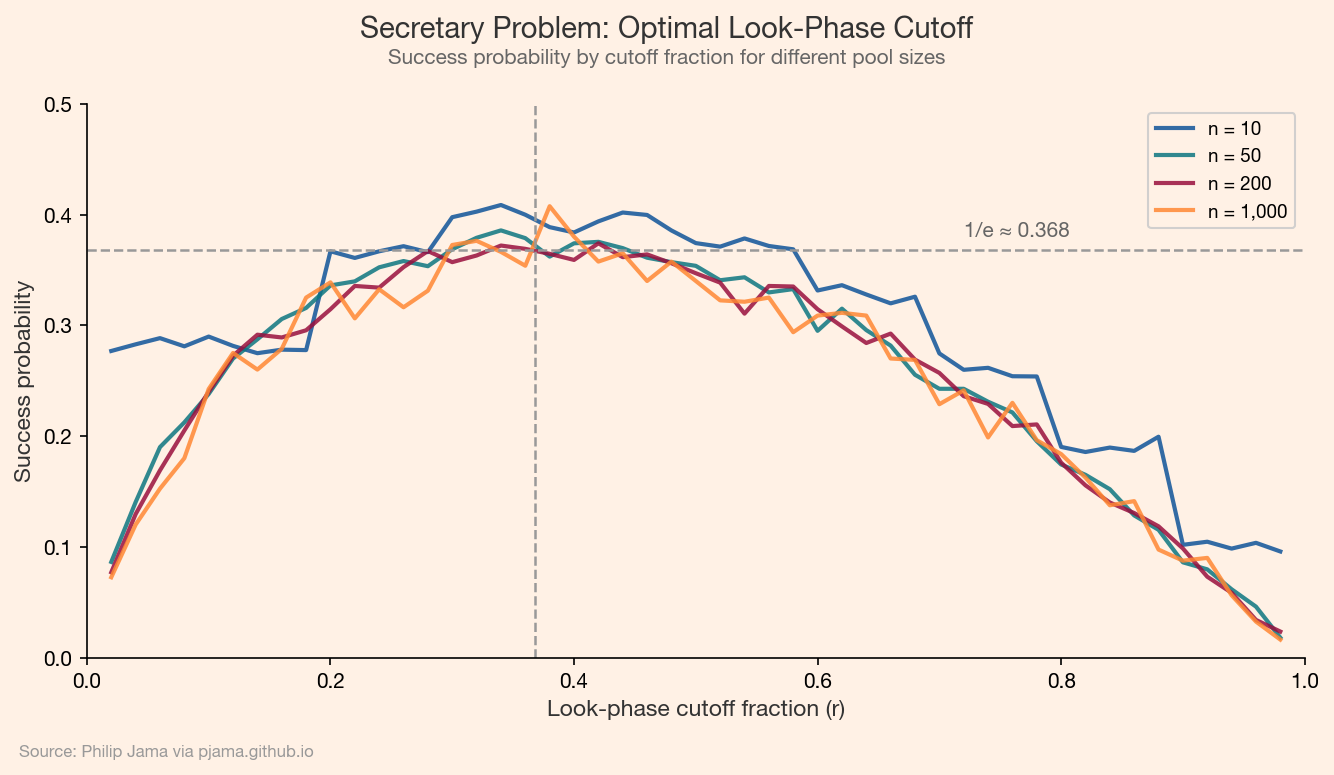
For a given cutoff r, the probability of selecting the best candidate can be written as a sum: for each position i > r, the best candidate is at position i and the best of the first i-1 candidates falls in the look phase (positions 1 through r). This leads to:
$$P(\text{win} \mid r) = \frac{r}{n} \sum_{i=r+1}^{n} \frac{1}{i-1}$$
As $n \to \infty$, this sum approximates $-\frac{r}{n} \ln!\left(\frac{r}{n}\right)$. Maximizing over the ratio $r/n$ gives the optimal fraction $1/e$, and the maximum probability converges to $1/e$.
The secretary problem isn't just a mathematical curiosity -- it maps onto many sequential decision problems:
In each case, the core tension is the same: explore too little and you miss better options; explore too long and the best options are gone.
The classic problem has spawned a rich family of variants:
n: When you don't know how many candidates exist, the strategy adapts using a time-based cutoff.k candidates instead of one, the optimal look phase shrinks.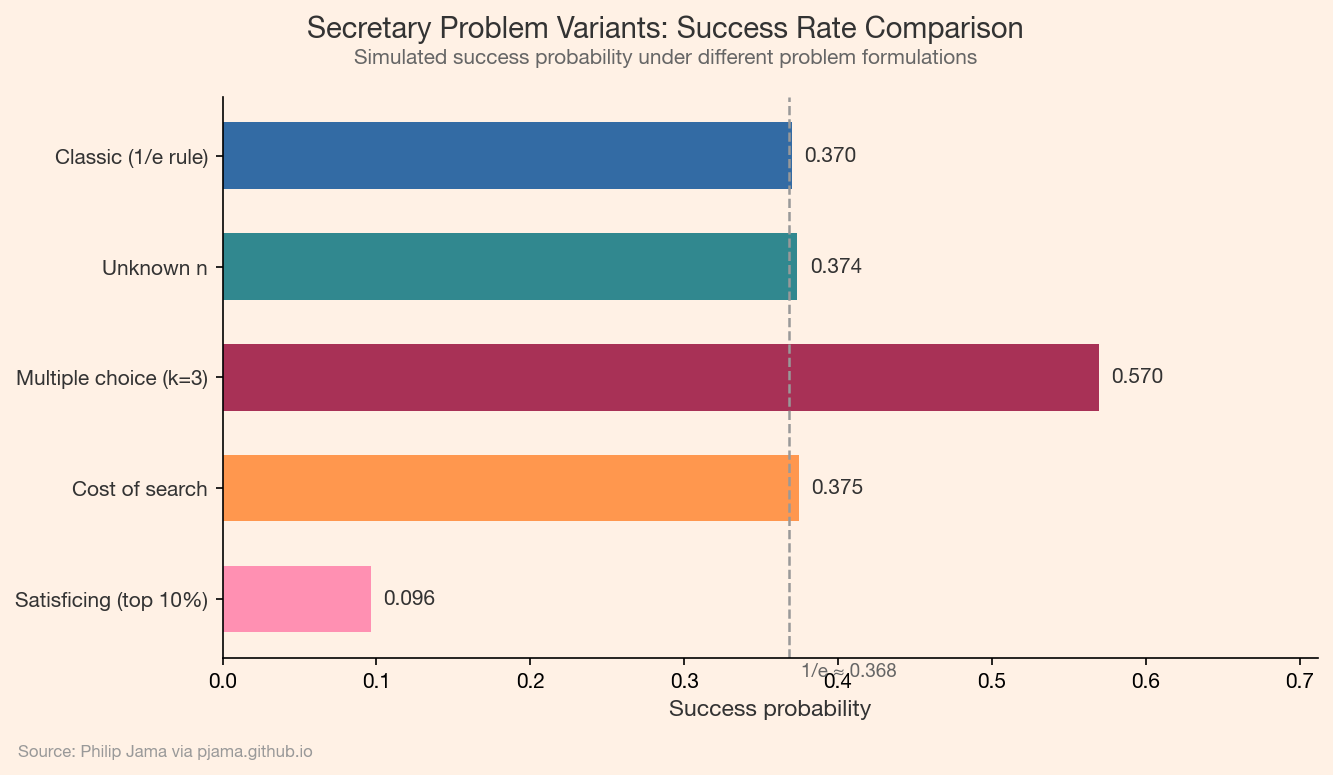
The secretary problem is the gateway to optimal stopping theory: the mathematics of deciding when to take an action to maximize reward. Related problems include:
The secretary problem teaches a deep lesson about the explore-exploit tradeoff: gathering information has value, but so does acting on it. The 37% rule gives a principled answer to "how long should you keep looking?" -- and the fact that it works regardless of the pool size makes it one of the most practically useful results in decision science.
If you're exploring related work and need hands-on help, I'm open to consulting and advisory. Get in touch›