Articles /Network Graph Analysis /Part 6
GraphRAG: Retrieval-Augmented Generation over Graphs
Graph-based retrieval for grounding LLM generation in structured, relational context
GraphRAGKnowledge GraphsLLMPythonNetworkX
Articles /Network Graph Analysis /Part 6
GraphRAGKnowledge GraphsLLMPythonNetworkX
Standard RAG retrieves text chunks by vector similarity. GraphRAG instead retrieves subgraphs -- connected neighborhoods of relevant entities and their relationships. This preserves structural context that chunked retrieval loses: how concepts relate, what path connects a question to an answer, which entities bridge different topics. Where Part 5 (LLM-Augmented Knowledge Graphs) built knowledge graphs from LLM output, this article uses those graphs as a retrieval backend.
Consider a knowledge graph built from news articles about global trade, geopolitics, and macroeconomics -- a "world graph" where nodes are countries, leaders, organizations, companies, and macro factors, and edges encode relationships like trade partnerships, policy influence, and economic exposure. A user asks: "How do US tariffs on China affect European automakers?" Vector search might retrieve a chunk about US-China tariffs and another about European car sales, but it cannot connect them. Graph retrieval starts at the "US tariffs" node, traverses edges through "China", "trade", "European Union", and "automotive industry", and returns a connected subgraph that traces the causal chain.
The following example builds a simplified version of such a world graph. Nodes carry a type attribute (country, person, organization, company, macro factor) and edges carry a sentiment (positive, negative, neutral). The visualization highlights the query neighborhood when asking about a specific entity's connections.
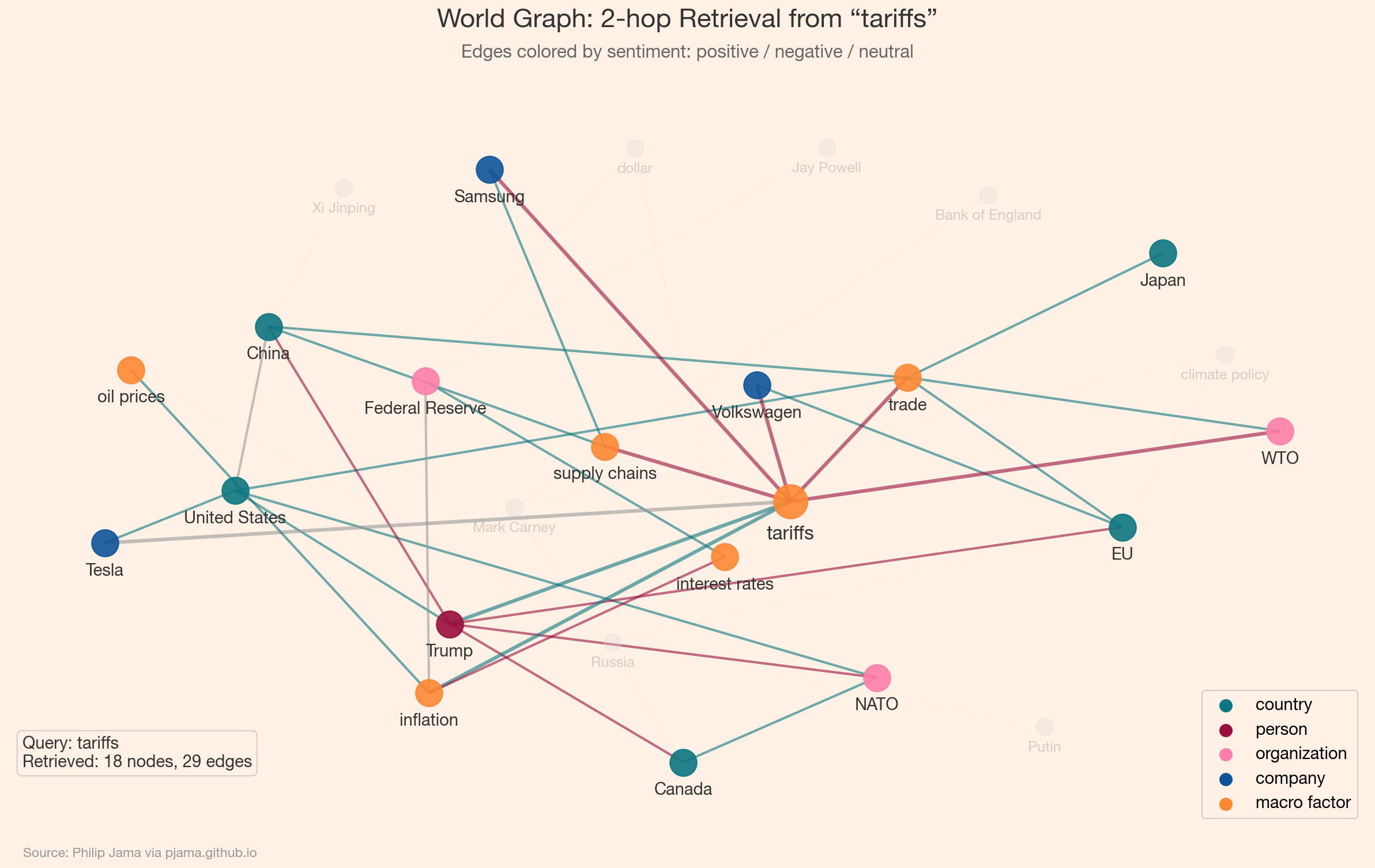
The retrieved subgraph around "tariffs" pulls in trade partners, affected companies, and inflationary consequences -- context that a flat vector search over article chunks would struggle to assemble coherently. Edge sentiment (green for positive, red for negative) adds a dimension that pure text retrieval cannot represent.
A GraphRAG system has four stages:
The simple k-hop neighborhood used above retrieves every node within a fixed number of edges. This works for small, uniform graphs but becomes noisy on real knowledge graphs where some 2-hop neighbors are highly relevant and others are incidental. More sophisticated distance metrics produce tighter, higher-quality subgraphs.
Instead of a hard hop cutoff, Personalized PageRank (PPR) runs a random walk that restarts at the query node with probability alpha. Nodes visited frequently by the walk receive high scores regardless of their exact hop distance. This naturally favors well-connected, structurally central neighbors over peripheral ones -- a node 3 hops away through a dense cluster may score higher than a 1-hop neighbor on a dead-end branch. PPR is the retrieval backbone of several production GraphRAG systems.
When nodes carry vector embeddings (from an LLM, a GNN, or a knowledge graph embedding model like TransE), retrieval can combine graph distance with embedding similarity. A common approach scores candidate nodes as a weighted blend of shortest-path distance and cosine similarity to the query embedding. This captures both topological proximity and semantic relevance -- two nodes far apart in the graph but close in meaning (synonyms, paraphrases) still get retrieved.
The resistance distance from Part 3 also applies here: it measures connectivity between two nodes accounting for all paths, not just the shortest. In retrieval terms, a node connected to the query through many redundant paths is more "reachable" than one connected by a single fragile edge. Ranking by effective conductance (the inverse of resistance distance) naturally weights robustly connected neighbors higher. For an applied example, see the Organizational Network Analysis ↗ project, which uses resistance distance to surface connection recommendations from calendar data.
Building GraphRAG from scratch clarifies the mechanics, but production systems typically rely on open-source frameworks that handle the plumbing. The ecosystem is maturing quickly.
LangChain's graph_rag integration provides a GraphRetriever that combines unstructured vector similarity search with structured metadata traversal. The key insight is that document metadata (tags, categories, source references) already forms a graph -- edges are defined by shared metadata fields. The retriever starts with a semantic search to find seed documents, then traverses metadata relationships to pull in structurally connected context. It supports pluggable vector stores (AstraDB, Cassandra, OpenSearch, Chroma) and offers built-in traversal strategies -- an eager strategy that expands to all neighbors within a depth limit, and MMR (Maximal Marginal Relevance) that balances relevance with diversity.
Microsoft's GraphRAG is an end-to-end pipeline that uses LLM extraction to build a knowledge graph, detects communities via Leiden clustering ↗, generates community summaries, and retrieves at multiple levels of abstraction -- local (entity neighborhoods) and global (community summaries). The global retrieval mode is distinctive: rather than traversing from a seed node, it queries pre-computed community summaries, enabling the system to answer broad questions ("What are the main themes in this corpus?") that entity-level retrieval cannot address.
Neo4jGraph integration that translates natural-language questions into Cypher queries, combining the flexibility of a graph database with LLM-powered query generation.The common pattern across all these frameworks is hybrid retrieval: vector search for semantic matching, graph traversal for structural context. The frameworks differ in how they construct the graph, what traversal strategies they offer, and how they serialize the retrieved subgraph into LLM context.
GraphRAG shines when answers require multi-hop reasoning, when entity relationships matter, or when the knowledge base has rich relational structure. Vector search is simpler, faster, and sufficient when questions map directly to text passages. In practice, hybrid approaches -- vector retrieval for initial candidates, graph traversal for context expansion -- often outperform either alone.
GraphRAG treats graph structure as a retrieval mechanism. Graph neural networks go further -- learning to encode that structure directly into vector representations.
If you're exploring related work and need hands-on help, I'm open to consulting and advisory. Get in touch›