Articles /Decision Science /Part 4
Causal Inference from Observational Data
Propensity scores, difference-in-differences, and what randomization buys you
Decision ScienceCausal InferenceObservational StudiesPython
Articles /Decision Science /Part 4
Decision ScienceCausal InferenceObservational StudiesPython
Randomized experiments are the gold standard for causal claims. Part 1 (Online Experiments with a Bayesian Lens) showed why: random assignment ensures that treatment and control groups differ only in the treatment itself, so any observed difference in outcomes can be attributed to the intervention. But randomization is not always possible. Ethical constraints, organizational realities, or the simple fact that the intervention already happened can rule out a controlled experiment.
Causal inference from observational data is the set of methods for estimating treatment effects when you cannot control assignment. The core challenge: without randomization, treated and untreated groups may differ systematically. Any naive comparison confounds the treatment effect with pre-existing differences. Every method in this article attacks that confounding problem from a different angle.
In a randomized experiment, treatment assignment is independent of all covariates, observed and unobserved. This independence makes the average outcome difference an unbiased estimator of the causal effect. Remove randomization and that guarantee disappears.
Consider a company that rolled out a new onboarding flow to users who signed up on weekdays. Weekend users kept the old flow. Comparing conversion rates directly would confuse the effect of the new flow with any weekday-vs-weekend differences in user behavior. The treatment (new onboarding) is confounded with the covariate (day of week).
The Rubin causal model defines the causal effect for unit i as Y_i(1) - Y_i(0): the difference between the outcome under treatment and the outcome under control. The fundamental problem of causal inference is that you only observe one of these two potential outcomes for each unit. The other is the counterfactual.
All observational methods try to construct a credible estimate of the missing counterfactual. They differ in what assumptions they require and how they construct comparison groups.
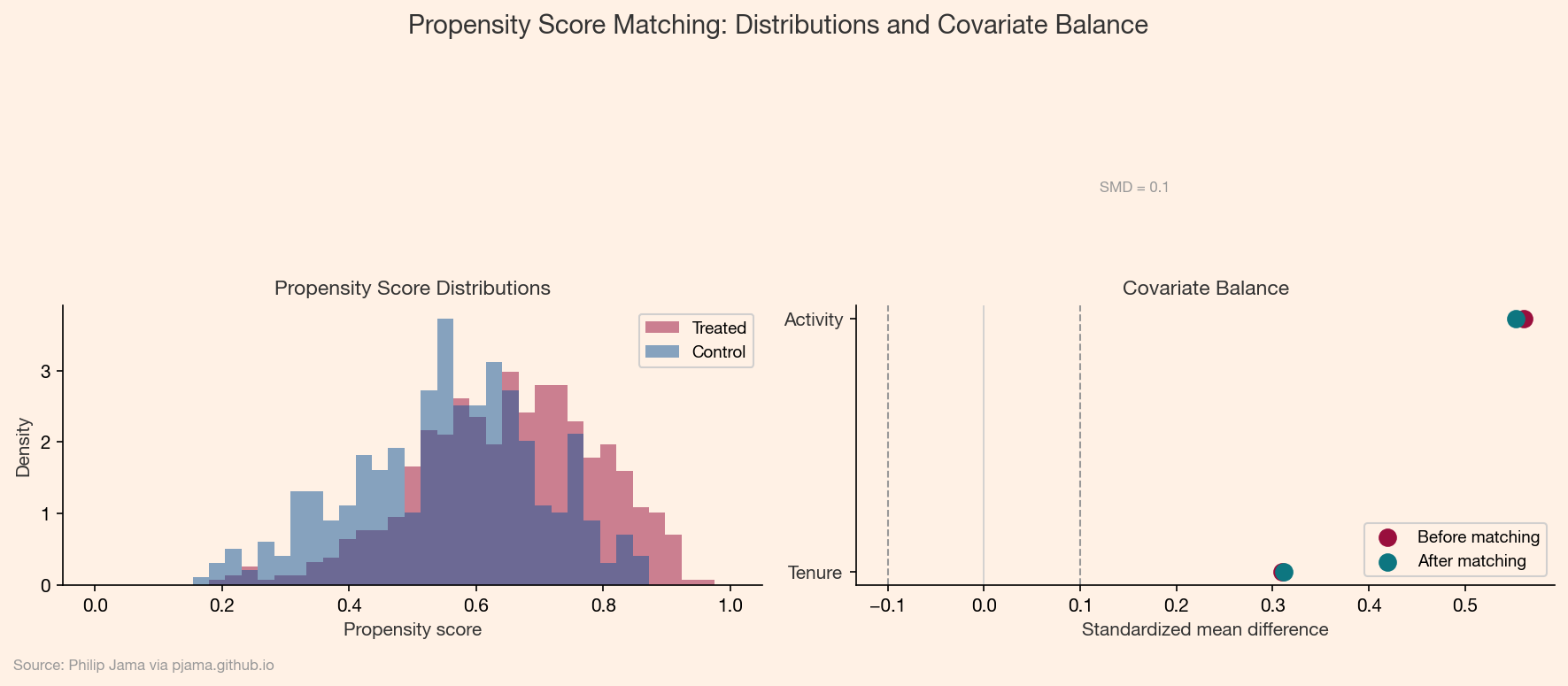
The propensity score is the probability of receiving treatment given observed covariates: e(X) = P(T=1 | X). Rosenbaum and Rubin (1983) showed that conditioning on the propensity score balances all observed covariates between treated and untreated groups, mimicking the balance that randomization would provide.
Two common approaches use the propensity score:
For each treated unit, find one or more untreated units with a similar propensity score. The matched pairs form a pseudo-randomized sample. The treatment effect estimate is the average outcome difference within matched pairs.
Matching works well when the propensity score distributions for treated and untreated groups overlap substantially. When overlap is poor (some treated units have no comparable controls), the method breaks down and honest reporting requires trimming those units.
Inverse probability weighting (IPW) reweights observations to create a pseudo-population where treatment assignment is independent of covariates. Treated units receive weight 1/e(X) and control units receive weight 1/(1-e(X)). The weighted average outcome difference estimates the average treatment effect.
IPW avoids discarding unmatched units but is sensitive to extreme propensity scores. When e(X) is close to 0 or 1, the weights explode and variance increases sharply. Stabilized weights and weight trimming mitigate this.
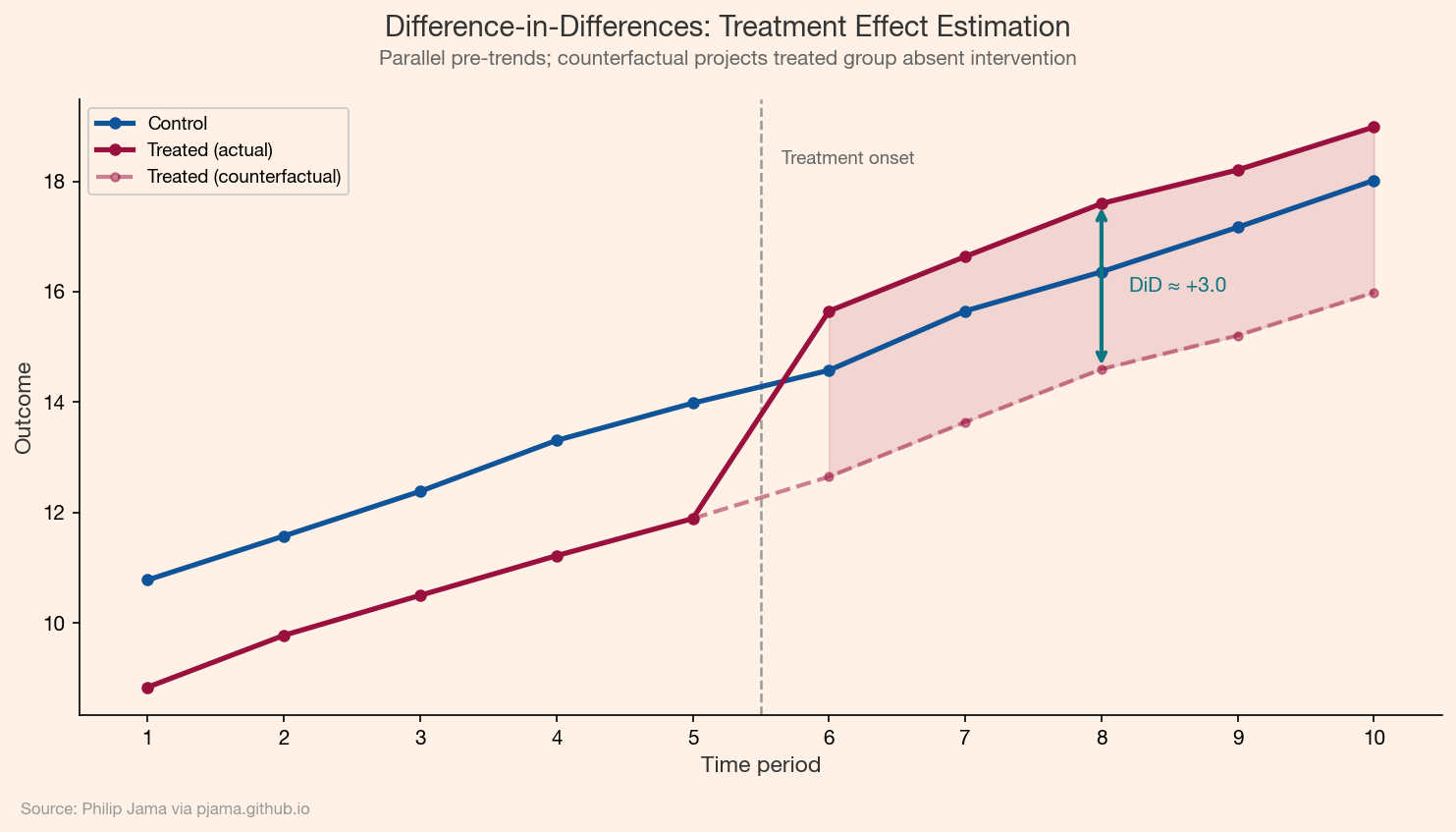
Difference-in-differences (DiD) exploits a natural experiment where treatment timing varies across groups. The method compares the change in outcomes before and after treatment for the treated group against the same change for the control group. The "double difference" removes time-invariant confounders (group-level) and common time trends (period-level).
The identifying assumption is parallel trends: absent the treatment, the treated and control groups would have followed the same trajectory. This assumption is untestable in the post-treatment period, but you can check whether pre-treatment trends are parallel as a plausibility diagnostic.
When unobserved confounders bias the treatment effect, an instrumental variable (IV) can recover a causal estimate. An instrument Z must satisfy three conditions:
Z is correlated with the treatment.Z affects the outcome only through the treatment.Z is independent of unobserved confounders.The classic example: distance to a college as an instrument for years of education when estimating the effect of education on earnings. Distance affects whether someone attends college but (arguably) does not directly affect earnings.
The IV estimator uses two-stage least squares. In the first stage, regress treatment on the instrument. In the second stage, regress the outcome on the predicted treatment values. The resulting coefficient estimates the local average treatment effect (LATE): the causal effect for the subpopulation whose treatment status is influenced by the instrument.
All of these methods benefit from thinking in terms of directed acyclic graphs (DAGs). A DAG encodes assumptions about which variables cause which others. Given a DAG, you can read off which variables to condition on (the adjustment set) and which to leave alone.
The connection to graph analysis runs deep. Part 9 of the Network Graph Analysis series covers DAGs, d-separation, and do-calculus in detail. The key principle here: conditioning on a collider (a variable caused by both treatment and outcome) introduces bias rather than removing it. Drawing the DAG before choosing a method prevents this mistake.
The right method depends on what you can assume:
| Method | Key Assumption | Handles Unobserved Confounders? |
|---|---|---|
| Propensity score matching | Selection on observables | No |
| Inverse probability weighting | Selection on observables | No |
| Difference-in-differences | Parallel trends | Time-invariant ones |
| Instrumental variables | Valid instrument exists | Yes (for compliers) |
No method is assumption-free. The honest practice is to state the identifying assumption, assess its plausibility, and run sensitivity analyses to check how fragile the estimate is to violations.
Observational methods estimate effects when the experiment is already over. A different practical challenge arises when the experiment is still running: how to monitor accumulating evidence and decide when enough data has arrived. Sequential testing and early stopping provides the formal machinery, connecting the Bayesian posterior monitoring introduced in Part 2 (Bayesian Sample Efficiency) with rigorous stopping rules.
Observational methods estimate effects after the fact. A complementary problem arises during an experiment: when should you stop collecting data and declare a result? Sequential testing formalizes early stopping.
If you're exploring related work and need hands-on help, I'm open to consulting and advisory. Get in touch›